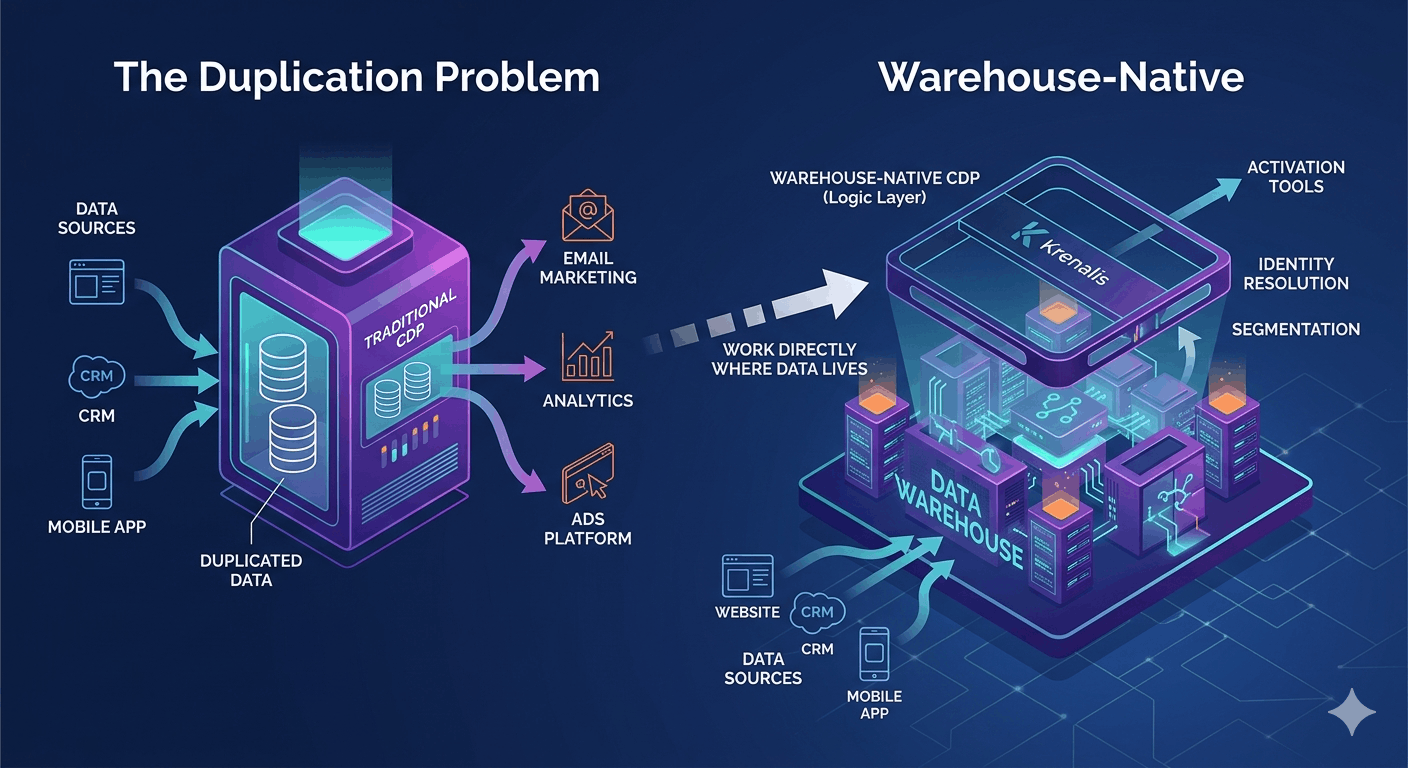
When people talk about Customer Data Platforms, they usually describe a fairly standard model: you collect data from multiple sources, send everything into the CDP, build unified customer profiles, and then activate that data across your marketing and product stack. This approach has become the norm and, for a long time, it has worked well.
But there is an assumption behind this model that is rarely questioned: to make customer data usable, you first need to copy it.
Why duplication became the default
If you look at how most traditional CDPs are built, the architecture is quite consistent:
Data is collected from websites, mobile apps, CRMs, and other systems. It is then ingested into the CDP, stored, processed, and enriched. Identity resolution happens inside the platform, and the resulting profiles are pushed to downstream tools.
From a product perspective, this makes a lot of sense, because it allows the CDP to be self-contained, simplifies onboarding and gives teams a clean, unified interface to work with; but this design also introduces a structural consequence: customer data ends up living in more than one place.
What duplication really means in practice
At first, duplicating data may not seem like a problem. In fact, it often feels convenient. But as systems grow, the side effects start to emerge.
You might notice that the same metric has slightly different values depending on where you look at it; you might find yourself asking which system is actually the source of truth, and you might need to maintain pipelines just to keep datasets aligned.
Over time, duplication stops being an implementation detail and becomes part of the architecture; and once it is part of the architecture, it affects everything:
* Governance becomes more complex because data is spread across systems.
* Debugging becomes harder because logic is fragmented.
* Operational overhead increases because every copy needs to be maintained.
None of this is necessarily a deal breaker, but it does raise a question:
Is this duplication really necessary?
Starting from a different assumption
An alternative way to approach the problem is to start from a different premise.
In many companies today, the data warehouse already contains the most complete and reliable version of customer data: it stores events, transactions, user attributes, and often a large part of the business logic.
If that is the case, then copying all that data into another system just to process it may not always be the best option: instead of building a CDP that stores data, you can think of a CDP as something that operates on top of the data you already have.
What this looks like in practice
In a warehouse-native approach, the flow is simpler, at least conceptually.
* Events are collected and sent directly to the data warehouse.
* There is no intermediate storage layer inside the CDP.
Once the data is there, identity resolution becomes a transformation problem.
For example, imagine a user who first visits your website anonymously, then later logs in.
In a traditional CDP, the platform would handle the merge internally.
In a warehouse-native model, the same logic is expressed explicitly: You might have a table of events with fields like anonymous_id and user_id.
When a login event occurs, you can associate the anonymous identifier with the known user.
From there, you can build a unified view using SQL transformations.
The important difference is not the outcome.
In both cases, you end up with a unified customer profile.
The difference is where the logic lives and how visible it is.

Making identity resolution explicit
One of the most interesting effects of this approach is that identity resolution stops being a black box.
Instead of being hidden inside a platform, it becomes part of your data model, so you can inspect it, version it, and evolve it over time.
If something looks wrong, you can trace it back through the transformations.
If your matching logic changes, you can update it like any other piece of code.
This does not make the problem easier, because Identity resolution is inherently complex, but it does make it more transparent.
Building the customer profile in the warehouse
Once identities are resolved, building a customer profile becomes a natural extension of your data workflows.
You can aggregate events, compute metrics, and define segments directly in the warehouse.
For example, you might calculate:
- when a user was first seen
- how often they interact with your product
- whether they have made a purchase
All of this lives in tables that are accessible to the rest of your organization.
Analytics, product, and marketing teams can all work from the same dataset, without needing to reconcile different systems.
Activation without moving data around
Activation also changes slightly: instead of pulling data out of a CDP database, you can push it directly from the warehouse to the tools that need it.
In some cases, tools can even read from the warehouse directly.
Again, the goal is not to remove functionality, but to reduce the number of steps and systems involved.
The trade-offs you should expect
This approach is not a shortcut, however, because although it removes one layer of complexity, it introduces another:
- Performance is one of the first things to consider: running identity resolution on large datasets can be compute-intensive, especially as data grows.
- Cost also shifts: you are no longer paying for duplicated storage inside a CDP, but you may consume more warehouse compute.
- Real-time use cases require careful design: while traditional CDPs are often optimized for immediate updates, warehouse-based approaches may rely on micro-batching or streaming pipelines.
- Finally, there is a question of ownership: when identity logic lives in your warehouse, your team is responsible for it, and this requires a certain level of data engineering maturity.
When this model makes sense
This way of building a CDP tends to work well in organizations that already have a solid data foundation.
If your warehouse is central to your architecture, and your team is comfortable working with data models and transformations, the benefits can be significant.
This is also the direction we are exploring in our own work on customer data infrastructure, where reducing duplication and keeping logic close to the data has proven to be a consistent design principle.
A shift in perspective
What makes this approach interesting is not just the technical differences.
It reflects a broader shift in how data systems are evolving: instead of building tools that own and replicate data, more systems are starting to operate directly on top of existing data layers.
In this context, the role of a CDP changes: it becomes less about storing data, and more about enabling teams to work with it effectively.
Final thoughts
There is no single correct way to build a CDP.
Different architectures exist because different problems need to be solved.
However, if your data warehouse already contains your most complete and reliable customer data, it is worth asking a simple question.
Do you really need to copy that data somewhere else to make it useful?
Or can you work directly where the data already lives?
If you are exploring similar approaches or have faced these trade-offs in practice, we would be interested in hearing your perspective.
Let's talk about your data architecture
Navigating the shift toward a warehouse-native approach comes with its own set of engineering and strategic choices. Whether you are looking to optimize your current setup, reduce data duplication, or build a more transparent customer data infrastructure, we are here to help you figure out the best path forward.
Get in touch with the Krenalis team to share your challenges or discuss how to make your data warehouse the true engine of your growth.